
上一講我們講了何謂〝精準〞的找出我們所需要的,這一講我們來講講模型的部份。
■ 化繁為簡
當我們大量的搜尋資料之後,就會一個問題,這些這些數據實在太雜亂了,我們很難去從這些雜亂的數據當中找出我需要的資料,所以首先我們必須要先化繁為簡,透過〝模型〞來幫我們處理複雜的數據,進而讓我們可以進一步的透過〝處理完的數據〞來幫助我們做決策。
所以,透過「化繁為簡」的原理來探討,我們今天這篇文章只講二個重點:
- NES 模型;
- 人機分工。
一、NES 模型 ( 5 狀態 10 指標 )
要注意的數據這麼多,要怎麼即時掌握目前的消費者狀態呢??
ー ー 化繁為簡,只需要透過 NES 的 5 個狀態,我們就能快速掌握到客戶的即時動態資訊。
這本書的核心其實就是在講 NES 模型,主要是關注〝客戶〞的所有狀態,它透過很簡單的 5 個狀態、 10 個指標就可以讓我們輕易掌握到客戶的即時動態資訊,首先我們就先來了解一下 NES 模型。
■ NES 模型
NES 完全不在乎年齡、性別等傳統人口統計特徵,而是根據消費者具體的購買行為,將消費者分為三種,一是首次購買的新顧客 N(New Customer),二是支撐主要營收來源的既有顧客 E(Existing Customer,主力顧客 E0 +瞌睡顧客 S1 +半睡顧客 S2),以及三是沉睡顧客 S(Sleeping Customer)。(詳見下圖: 從 N-E-S 看顧客消費狀態變化)。
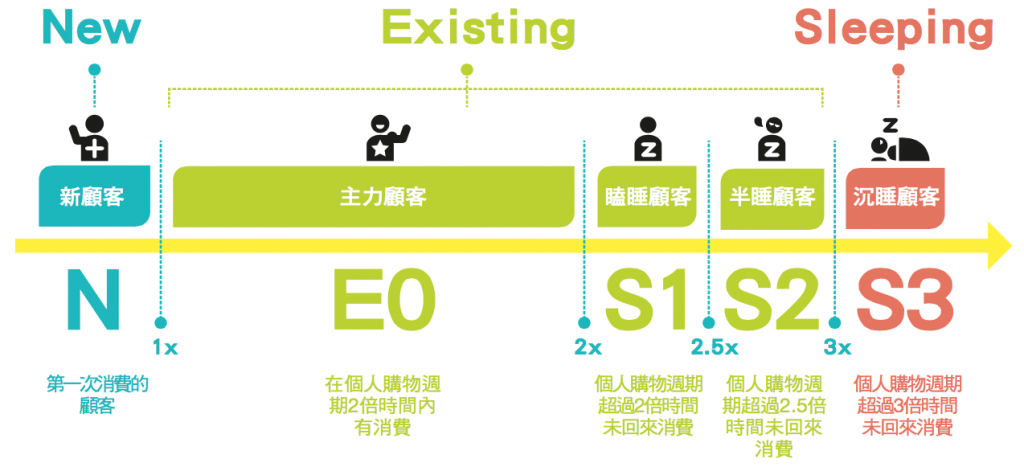
NES 模型根據消費者的個人購物週期,分為首次購買的新顧客 ( NEW )、支撐主要營收來源的既有顧客 ( Existing ),和回購於低於 10% 的深睡顧客 ( Sleeping Customer )。而既有顧客又可分為 E0 主力顧客、S1 嗑睡顧客和 S2 半睡顧客。
而 NES 模型是為了即時掌握顧額的變動性而設以計,根據消費者實際交易數據演算,並配合資料更新進行動態修正。共分為 N、E0、S1、S2、S3 五種標籤,而隨著沉睡度愈來愈深,品牌能有夠有效喚醒的機會愈低、而目對的喚醒成本也將大幅增加。所以,即時掌握每個消費者的實際狀態,是大數據行銷最重要的第一步。(詳見下圖: 從 N-E-S 看顧客動態變化)。
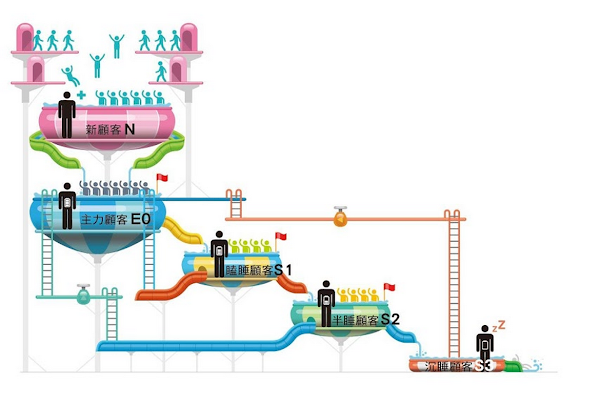
從消費者當中必然有新顧客 ( N )、主的顧客 ( E0 ) 一直到沉睡顧客 ( S3 ) 等五種狀態,然後又發現顧額不斷地往下一個階段流失,很多人看到這邊就已經開始垂頭喪氣。但是,流失是可以被控制和改善的 ( 喚醒 ) 的,行銷人應該在不同的階段,設定對應的行銷活動,比方說,在顧客 E0 階段的規劃顧客忠設度計劃,或是在 S1、S2 和 S3 不同的停滯階段,設計喚醒方案。
水往低處流,要把愈低層的水抽上來,需要更大的動能。同理, NES 顧額模型就像五個層層向下的水槽,為預防顧客不斷地從主力顧客 ( E0 ) 慢慢滑落到無法挽回的沉睡顧客 ( S3 ),我們不但要建立有效的預警和調節機制,而且這套機制,必須藉由大數據的演算和預測,做到「智能控制」,基於人機分工的策略下,實時偵測、適時調整,而且一切的控制都是基於演算和預測,估到「智能控制」,基於人機分工的策略下,實時偵測、適時調整,而且一切的控制都是基於演算預測後的最佳決策。
■ 營收方程式
我們再來看看本書提出對於營收方程式: 營收(revenue)= 有效顧客數 X 顧客活躍度 X 客單價。
獲利是企業經營的共同目標,影響獲利的因子有很多,但主要影響營收目標的是:顧客數增加、客單提高和活躍度提升;我們可以發現 NES 模型主要在幫助我們提升「有效顧客數 X 顧客活躍度」的部份,進而也會營收最重要的部份。
很多店家下滑的主要原因其實是,高貢獻度的忠誠顧客大量而且快速的流,活動提升的新顧額對營收幫助渺小,當務之急應該先找出忠誠顧額的流失原因,制定顧額挽回方案,先固本補破,才去找新客戶。
二、人機分工
ー ー 把「重複」的事情交給機器去做,讓人專注做決策和調整模型即可。
就算減化了關鍵指標,但我們要做的事情仍然一樣很多?
■ 為什麼要人機分工
首先,我們要做大數據的第一個要點就是〝人機分工〞,為什麼要人機分工,很重要的其中一個原因就是我們的大腦其實〝不善於處理大數〞,舉例來說,一個算式 1 + 5 我們很快就可以計算出來結果,但如果是 10000000 + 50000000 ,我們可能就必須要花費更多的時理去理解這個數;然後對機器而言,計算的問題是非常簡單的,所以我們必須各司其職,做各自擅長的事。
因為我們人類不善於處理複雜的事情,所以在處理大數據上也是如此,龐大的數據資料對我們來說太複雜,沒辦法去找出其中的規律進而做下一節的處理和決策,所以我們必須化繁為簡,讓〝機器〞去做複雜的資料處理,篩選出我們需要的重要指標,進而我們人類來做下一步的決策即可。簡單的話,就是讓機器做機器擅長的事,人做人擅長的事,亦即自動化。
■ Log 偵測 – 不干擾的蒐集顧客資料:
在過往,我們要了解額客需求,我們第一時間想到的就是問卷調查,然而問卷調查一來必須要付出大量的時間、精力和成本來取得顧客的資訊、二來也必須佔用顧客的時間,增加他們的負擔;然而在大數據時代,我們不需要有形中去取得顧客的行為資訊,工程師可以在每個軟體後面附加 Log (*註1),主動偵測人的活動日誌,了解他的歷史瀏記錄;透過無形偵測,不干擾、不介入,企業即能獲知最真實的使用者意向。
透過 Log 幫助我們取得行為數據,除了可以克服先前問卷可以造假而產生的不客觀問題之外,還可以幫助我們取得顧客〝更真實〞的行為意圖。
舉例來說,之前有一個研究發現,一家廠商在做新品的市場調查,推出的〝藍色〞款商品是否比原本的〝白色〞經典款佳,在談訪的過程當中,7 成左右的人們都說喜歡〝藍色〞款的產品,然後結束調察之後,讓這些人可以自由選擇這兩款顏色的產品當成贈品帶回家,結果大部份的卻選擇了〝白色〞經典款。
透過很多相關的心理研究,人們有時候會心不由衷而不自知,所以只有透過〝真實行為〞來判斷客戶的真實喜愛,才是更相對客觀的;除了我們可以透過線上取得之外,事實上,我們也可以將線下實體商店的數據給導入,而使得資料擁有更多維度的資料;什麼是消費者不會作假的數據呢?答案正是交易數據。透過線上 + 線上的數據整合,我們將擁有更多維護的資料,來供我們產生〝更精準〞資料分析。
■ 人的目標:做好、做對、做優
透過機器自動幫我們蒐集重要資訊之後,我們就可透把時間空閒出來,讓人做最善長的事,舉例來說,好的客服,不是一直纏著顧客問東問西、而是像一個偵探,發現異狀馬上跳出來解決。從顧客使用軌跡開始下滑時主動關心,預防事態擴大,不但能有效地經營顧客關係,更能大幅降低負面情緒的溝通成本。
我們還必須不斷的從源頭思考學習 ( Learning ),形成學習曲線達到內化,再透過內化不斷轉化,延展出更多創新的可能性,持續去的根據環境的真實反饋,隨時修正模式公式,透過我們反覆訓練 ( Trainning ) 讓模型更加反應真實,並且能夠提升效率,把事情做快。
機器可以把事快速做好,而人目標應是把事做好、做對、做優。
另外,透過模析分析幫我們之後,我們要必須要去設定〝自動化流程〞,讓機器在關鍵時間幫我們做正確的事,舉例來說:當我們自動偵測沉睡到 S3 用戶,我們可以透過自動化程式來幫我們自動發一封沉睡顧客喚醒的 eDM,如果他 48 小時有開信,則任務完成,若沒有,則再寄簡訊給他。
三、小結
在大數據時代,是以「人」為核心,而不是以「產品」為主軸。如果說商業最重要的就是獲利,而有什麼會影響獲利,行銷人不可能一天看千張報表,但如果目是獲利,我們可以從獲利公式 10 指標做降維思考,做出決策。在這一講當中,我們提到了大數據行銷營收方程式,包含了:
- 5 種狀態:新顧客、主力顧客、嗑睡顧客、半睡顧客、沉睡顧客。
- 10 指標:新增率、變動率、流失率、轉化率、活躍度、喚醒率 x 3 ( 嗑睡顧客、半睡顧客、沉睡顧客 )、客單價 x 2 ( 新顧客單價、主力顧客單價 )

我們會發現,勝負不在數據,觀點才能決定一切。所以詮釋的問題角度和觀點格外重要,我們必須要不斷地挖掘問題核心,不要一次用龐大計劃去解決所有問題,而是要每次只專注把一個問題給答好,然後選定一個觀點快速切入,形成解決方案。
問題的不同,會影響到數據的蒐集,而唯有問對問題,才能蒐集到正確而且有價值的關鍵數據。20/80法則,鎖定小而準的數據; 20/80 法則意指在所有的大數據裡,僅僅 20% 的數據就占據了高達 80% 的價值。
減法思維的好處是,每天只要監控這 10 個指標,出現問題就可以立即對症下藥,可以加快決策的速度以及提升決策的精準度。
我們下一講就來講講「大數據行銷」的實際應用與範例。
補充:
註1:Log 偵測
目前市上有許可以幫我們主動偵則的工具,例如 Google Analytics、Facebook Pixel、Mixpanel、Hotjar …等等
系列文章快速連結:
- 《大數據玩行銷》1:小而美的高效行銷
- 《大數據玩行銷》2:要如何提高數據預測的精準度
- 《大數據玩行銷》3:化繁為簡的NES模型和人機分工
- 《大數據玩行銷》4:數據行銷實際應用與應用場景
- [W2] 《大數據玩行銷》撰寫心得總結